Introduction to Zarr#
Learning Objectives:#
Understand the principles of the Zarr data format
Learn how to read and write Zarr stores using the
zarr-pythonlibraryExplore how to use Zarr stores with
xarrayfor data analysis and visualization
This notebook provides a brief introduction to Zarr and how to use it in cloud environments for scalable, chunked, and compressed data storage.
Zarr is a data format with implementations in different languages. In this tutorial, we will look at an example of how to use the Zarr format by looking at some features of the zarr-python library and how Zarr files can be opened with xarray.
What is Zarr?#
The Zarr data format is an open, community-maintained format designed for efficient, scalable storage of large N-dimensional arrays. It stores data as compressed and chunked arrays in a format well-suited to parallel processing and cloud-native workflows.
Zarr Data Organization:#
Arrays: N-dimensional arrays that can be chunked and compressed.
Groups: A container for organizing multiple arrays and other groups with a hierarchical structure.
Metadata: JSON-like metadata describing the arrays and groups, including information about data types, dimensions, chunking, compression, and user-defined key-value fields.
Dimensions and Shape: Arrays can have any number of dimensions, and their shape is defined by the number of elements in each dimension.
Coordinates & Indexing: Zarr supports coordinate arrays for each dimension, allowing for efficient indexing and slicing.
The diagram below from the Zarr v3 specification showing the structure of a Zarr store:
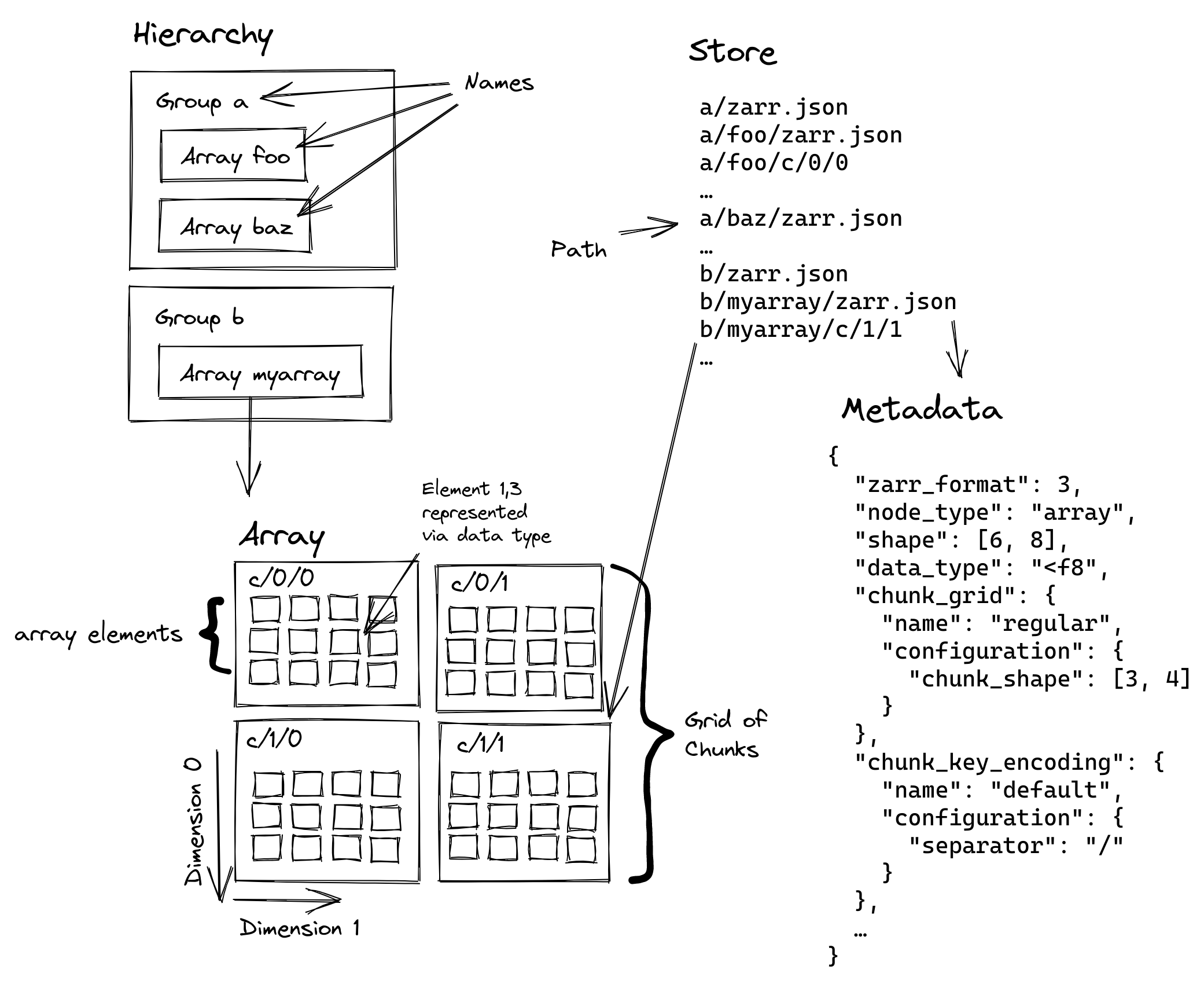
NetCDF and Zarr share similar terminology and functionality, but the key difference is that NetCDF is a single file, while Zarr is a directory-based “store” composed of many chunked files, making it better suited for distributed and cloud-based workflows.
Zarr Fundamenals#
A Zarr array has the following important properties:
Shape: The dimensions of the array.
Dtype: The data type of each element (e.g., float32).
Attributes: Metadata stored as key-value pairs (e.g., units, description.
Compressors: Algorithms used to compress each chunk (e.g., Zstd, Blosc, Zlib).
Example: Creating and Inspecting a Zarr Array#
Here we create a simple 2D array of shape (40, 50) with chunks of size (10, 10) ,write to the LocalStore in the test.zarr directory.
import pathlib
import shutil
import zarr
# Ensure we start with a clean directory for the tutorial
datadir = pathlib.Path("../data/zarr-tutorial")
if datadir.exists():
shutil.rmtree(datadir)
output = datadir / "test.zarr"
z = zarr.create_array(shape=(40, 50), chunks=(10, 10), dtype="f8", store=output)
z
<Array file://../data/zarr-tutorial/test.zarr shape=(40, 50) dtype=float64>
.info provides a summary of the array’s properties, including shape, data type, and compression settings.
z.info
Type : Array
Zarr format : 3
Data type : Float64(endianness='little')
Fill value : 0.0
Shape : (40, 50)
Chunk shape : (10, 10)
Order : C
Read-only : False
Store type : LocalStore
Filters : ()
Serializer : BytesCodec(endian=<Endian.little: 'little'>)
Compressors : (ZstdCodec(level=0, checksum=False),)
No. bytes : 16000 (15.6K)
z.fill_value
np.float64(0.0)
No data has been written to the array yet. If we try to access the data, we will get a fill value:
z[0, 0]
array(0.)
This is how we assign data to the array. When we do this it gets written immediately.
Attributes#
We can attach arbitrary metadata to our Array via attributes:
Zarr Data Storage#
Zarr can be stored in memory, on disk, or in cloud storage systems like Amazon S3.
Let’s look under the hood. The ability to look inside a Zarr store and understand what is there is a deliberate design decision.
z.store
LocalStore('file://../data/zarr-tutorial/test.zarr')
!tree -a {output}
!cat {output}/zarr.json
Hierarchical Groups#
Zarr allows you to create hierarchical groups, similar to directories. To create groups in your store, use the create_group method after creating a root group. Here, we’ll create two groups, temp and precip.
store = zarr.storage.MemoryStore()
root = zarr.create_group(store=store)
temp = root.create_group("temp")
precip = root.create_group("precip")
t2m = temp.create_array("t2m", shape=(100, 100), chunks=(10, 10), dtype="i4")
prcp = precip.create_array("prcp", shape=(1000, 1000), chunks=(10, 10), dtype="i4")
root.tree()
/
├── precip
│ └── prcp (1000, 1000) int32
└── temp
└── t2m (100, 100) int32
Groups can easily be accessed by name and index.
display(root["temp"])
root["temp/t2m"][:, 3]
<Group memory://140224515830080/temp>
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)
To get a look at your overall dataset, the tree and info methods are helpful.
root.info
Name :
Type : Group
Zarr format : 3
Read-only : False
Store type : MemoryStore
root.tree()
/
├── precip
│ └── prcp (1000, 1000) int32
└── temp
└── t2m (100, 100) int32
Chunking#
Chunking is the process of dividing Zarr arrays into smaller pieces. This allows for parallel processing and efficient storage.
One of the important parameters in Zarr is the chunk shape, which determines how the data is divided into smaller, manageable pieces. This is crucial for performance, especially when working with large datasets.
To examine the chunk shape of a Zarr array, you can use the chunks attribute. This will show you the size of each chunk in each dimension.
z.chunks
(10, 10)
When selecting chunk shapes, we need to keep in mind two constraints:
Concurrent writes are possible as long as different processes write to separate chunks, enabling highly parallel data writing.
When reading data, if any piece of the chunk is needed, the entire chunk has to be loaded.
The optimal chunk shape will depend on how you want to access the data. E.g., for a 2-dimensional array, if you only ever take slices along the first dimension, then chunk across the second dimension.
Here we will compare two different chunking strategies.
output = datadir / "c.zarr"
c = zarr.create_array(shape=(200, 200, 200), chunks=(1, 200, 200), dtype="f8", store=output)
c[:] = np.random.randn(*c.shape)
%time _ = c[:, 0, 0]
CPU times: user 195 ms, sys: 20.9 ms, total: 216 ms
Wall time: 110 ms
output = datadir / "d.zarr"
d = zarr.create_array(shape=(200, 200, 200), chunks=(200, 200, 1), dtype="f8", store=output)
d[:] = np.random.randn(*d.shape)
%time _ = d[:, 0, 0]
CPU times: user 1.85 ms, sys: 0 ns, total: 1.85 ms
Wall time: 1.61 ms
Object Storage as a Zarr Store#
Zarr’s layout (many files/chunks per array) maps perfectly onto object storage, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage. Each chunk is stored as a separate object, enabling distributed reads/writes.
Here are some examples of Zarr stores on the cloud:
Amazon Sustainability Data Initiative available from Registry of Open Data on AWS - Enter “Zarr” in the Search input box.
Xarray and Zarr#
Xarray has built-in support for reading and writing Zarr data. You can use the xarray.open_zarr() function to open a Zarr store as an Xarray dataset.
import xarray as xr
store = "https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/gpcp-feedstock/gpcp.zarr"
ds = xr.open_dataset(store, engine="zarr", chunks={}, consolidated=True)
ds
<xarray.Dataset> Size: 2GB
Dimensions: (time: 9226, latitude: 180, longitude: 360, nv: 2)
Coordinates:
* time (time) datetime64[ns] 74kB 1996-10-01 1996-10-02 ... 2021-12-31
* latitude (latitude) float32 720B -90.0 -89.0 -88.0 ... 87.0 88.0 89.0
* longitude (longitude) float32 1kB 0.0 1.0 2.0 3.0 ... 357.0 358.0 359.0
lat_bounds (latitude, nv) float32 1kB dask.array<chunksize=(180, 2), meta=np.ndarray>
lon_bounds (longitude, nv) float32 3kB dask.array<chunksize=(360, 2), meta=np.ndarray>
time_bounds (time, nv) datetime64[ns] 148kB dask.array<chunksize=(200, 2), meta=np.ndarray>
Dimensions without coordinates: nv
Data variables:
precip (time, latitude, longitude) float32 2GB dask.array<chunksize=(200, 180, 360), meta=np.ndarray>
Attributes: (12/45)
Conventions: CF-1.6, ACDD 1.3
Metadata_Conventions: CF-1.6, Unidata Dataset Discovery v1.0, NOAA ...
acknowledgment: This project was supported in part by a grant...
cdm_data_type: Grid
cdr_program: NOAA Climate Data Record Program for satellit...
cdr_variable: precipitation
... ...
standard_name_vocabulary: CF Standard Name Table (v41, 22 February 2017)
summary: Global Precipitation Climatology Project (GPC...
time_coverage_duration: P1D
time_coverage_end: 1996-10-01T23:59:59Z
time_coverage_start: 1996-10-01T00:00:00Z
title: Global Precipitation Climatatology Project (G...ds.precip
<xarray.DataArray 'precip' (time: 9226, latitude: 180, longitude: 360)> Size: 2GB
dask.array<open_dataset-precip, shape=(9226, 180, 360), dtype=float32, chunksize=(200, 180, 360), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 74kB 1996-10-01 1996-10-02 ... 2021-12-31
* latitude (latitude) float32 720B -90.0 -89.0 -88.0 ... 87.0 88.0 89.0
* longitude (longitude) float32 1kB 0.0 1.0 2.0 3.0 ... 357.0 358.0 359.0
Attributes:
cell_methods: area: mean time: mean
long_name: NOAA Climate Data Record (CDR) of Daily GPCP Satellite-Ga...
standard_name: lwe_precipitation_rate
units: mm/day
valid_range: [0.0, 100.0]Exercise
Can you calculate the mean precipitation for January 2020 in the GPCP dataset and plot it?
Solution
ds.precip.sel(time=slice('2020-01-01', '2020-01-31')).mean(dim='time').plot()
Check out our other tutorial notebook that highlights the CMIP6 Zarr dataset stored in the Cloud